The increasing adoption of digital platforms by government organizations necessitates a deeper understanding of user sentiment to enhance public services. This paper presents an AI-driven sentiment analysis framework focused on Arabic-language Twitter data related to Abu Dhabi's TAMM e-services platform. Utilizing the CRISP-DM methodology, this study collected and preprocessed over 3,000 Arabic tweets, applied machine learning algorithms including Logistic Regression, Naïve Bayes, SVM, Random Forest, and MLP, and evaluated their performance in classifying sentiment. The results reveal that Multinomial Naïve Bayes achieved the best balance of accuracy (79.4%) and training efficiency (0.68s). Comparative evaluations using Cohen's Kappa and Matthews Correlation Coefficient validate inter-model agreement. This work demonstrates the feasibility and value of leveraging Arabic sentiment analysis for real-time feedback, aligning with national strategies such as the UAE Happiness Index [1], [2].
Keywords: Sentiment Analysis, Arabic NLP, CRISP-DM, TAMM, Machine Learning, Public Services, UAE Happiness Index
I. INTRODUCTION
As governments embrace digital transformation, e-services like TAMM in Abu Dhabi aim to streamline service delivery and improve citizen satisfaction. Understanding public sentiment through social media provides actionable insights that support policymaking and service enhancement. Sentiment analysis, particularly for Arabic text, poses unique challenges due to linguistic complexity and dialectal variation [3], [4].
Previous research has explored various machine learning methods for sentiment analysis [3], with specific focus on Arabic sentiment modeling [4]. However, limited studies have applied these techniques to the domain of government e-services, especially in the Arabic-speaking context. This study bridges that gap by applying a structured data mining methodology (CRISP-DM) and comparative machine learning evaluation to Arabic tweets related to TAMM.
II. METHODOLOGY
This study followed the CRISP-DM methodology [5], a structured process that includes six major phases, applied specifically to sentiment analysis:
- Business Understanding: The primary objective was to extract and analyze public sentiment about the TAMM government e-service platform in Abu Dhabi to help enhance decision-making and improve user satisfaction.
- Data Understanding: We collected Arabic-language tweets related to TAMM using Tweet Flash [6]. This data was derived from both labeled sentiment datasets and live user-generated content.
- Data Preparation: Preprocessing was a critical step to ensure data quality and accuracy. The steps included removing non-Arabic words, emojis, URLs, and repeated characters; normalizing Arabic text by unifying spelling variations (إ/آ/أ → ا); tokenizing and applying TF-IDF vectorization; and merging normalized labeled data with TAMM tweets to form a unified dataset.
The full pipeline from tweet collection to model training and evaluation is shown in Figure 1.
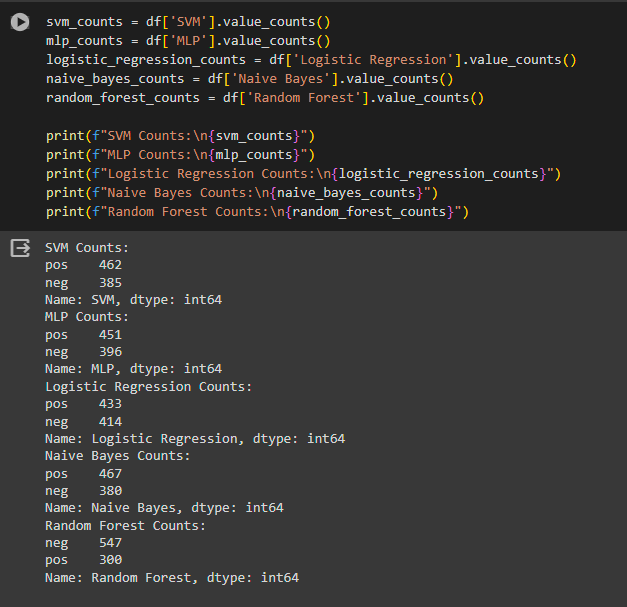 Modeling:
Modeling: Five classifiers were evaluated: Logistic Regression, Multinomial Naïve Bayes, SVM (C-SVC), Random Forest, and MLP. Naïve Bayes was selected for its simplicity and performance; SVM and MLP for capturing nonlinear patterns; and Random Forest for robustness against overfitting.
Evaluation: The dataset was split into 50% training, 10% validation, and 40% testing. Metrics included accuracy, training time, Cohen’s Kappa, and MCC [9], [10].
III. RESULTS
The performance of each model is summarized in Table 1. Figures 2 and 3 illustrate comparative accuracy and training time.
| Algorithm |
Accuracy (%) |
Training Time (s) |
Notes |
| Logistic Regression |
78.9 |
7.28 |
Balanced accuracy with fast training |
| Multinomial Naïve Bayes |
79.4 |
0.68 |
Best balance between accuracy and efficiency |
| SVM (C-SVC) |
79.1 |
3694.44 |
High test score but slowest training |
| Random Forest |
78.9 |
966.59 |
High test score; potential overfitting |
| MLPClassifier |
77.4 |
866.90 |
Complex model, risk of overfitting |
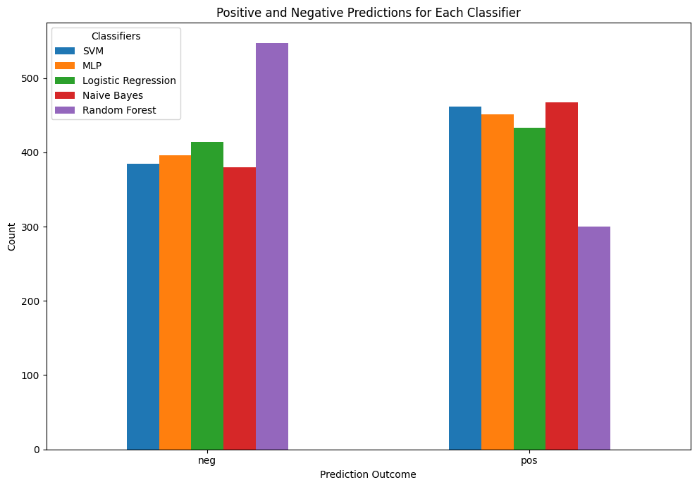

Agreement metrics indicated strong consistency across models:
- Cohen’s Kappa: Strong agreement between SVM and Logistic Regression (0.80).
- MCC: Validated model consistency across predictions.
These results highlight Multinomial Naïve Bayes as the most practical choice for real-time government e-service sentiment monitoring.
IV. DISCUSSION
Arabic sentiment analysis requires rigorous preprocessing and model selection. Naïve Bayes proved the most efficient, showing both strong accuracy and minimal training time, making it suitable for real-time deployment.
Sentiment word clouds were also generated, revealing positive themes like "سهل" (easy), "ممتاز" (excellent), and "سريع" (fast), and negative themes like "تأخير" (delay), "صعب" (difficult), and "غير واضح" (unclear).
V. CONCLUSION
This study demonstrates the feasibility of applying CRISP-DM-based sentiment analysis to Arabic Twitter data for Abu Dhabi's TAMM e-services. The Multinomial Naïve Bayes model was identified as the most effective classifier for real-time applications. These findings support the integration of AI-driven feedback mechanisms in government services, aligning with national strategies like the UAE Happiness Index.
Limitations include the focus on Modern Standard Arabic and reliance on social media users as a proxy for TAMM’s broader demographic. Future work should include dialect detection, deep learning models like AraBERT, and real-time dashboard integration.
REFERENCES
[1] Abu Dhabi Government, "TAMM – Abu Dhabi Government Services", 2018. [Online]. Available: https://www.tamm.abudhabi/
[2] The Official Portal of the UAE Government, “Happiness and National Agenda”, 2023. [Online]. Available: https://u.ae/en/about-the-uae/the-uae-government/government-of-future/happiness
[3] M. Wankhade, A. C. S. Rao, and C. Kulkarni, "A survey on sentiment analysis methods, applications, and challenges," Artificial Intelligence Review, 55(7), 5731–5780, 2022.
[4] S. Mohammad, "Sentiment Analysis in Arabic," 2021. [Online]. Available: https://saifmohammad.com/WebPages/ArabicSA.html
[5] C. Schröer, F. Kruse, and J. M. Gómez, "A systematic literature review on applying CRISP-DM process model," Procedia Comput. Sci., 181, 526–534, 2021.
[6] Shane, “Tweet Flash”, Apify. [Online]. Available: https://apify.com/shanes/tweet-flash
[7] M. I. Alfarizi, L. Syafaah, and M. Lestandy, “Emotional Text Classification Using TF-IDF And LSTM,” JUITA, 10(2), 225–232, 2022.
[8] H. T. Sueno, B. D. Gerardo, and R. P. Medina, "Multi-class document classification using SVM based on improved Naïve Bayes vectorization," Int. J. Adv. Trends Comput. Sci. Eng., 9(3), 2020.
[9] G. Rau and Y. S. Shih, “Evaluation of Cohen's kappa and other measures of inter-rater agreement,” J. Engl. Acad. Purp., 53, 2021.
[10] J. Yao and M. Shepperd, “Assessing software defect prediction performance: Why using the Matthews correlation coefficient matters,” Proc. Eval. Assess. Softw. Eng. Conf. (EASE), 2020.
[11] S. H. Janjua et al., “Multi-level aspect based sentiment classification of Twitter data using hybrid approach in deep learning,” PeerJ Comput. Sci., 7, e433, 2021.