Study evaluates Russian large language models Yandex GPT-5 and GigaChat 2.0 MAX against global leaders—ChatGPT 4o, Grok 3, and DeepSeek V3—in business-relevant tasks. This study uses a mixed-method approach, combining custom-designed tasks, LM Arena data, and standardized benchmarks to evaluate logic, mathematics, programming, content creation, and image generation. Russian models match global peers in logic and mathematics, lag slightly in programming and creativity due to resource constraints, and excel in native language tasks, partially outperforming Western models. Their performance aligns closely with international standards, with potential to lead in Russian tasks, reflecting Russia’s strategic AI.
Keywords: AI development, Russian AI, artificial intelligence, Yandex GPT-5, GigaChat 2.0 MAX
I. INTRODUCTION
The global artificial intelligence (AI) landscape has entered an era of geopolitical stratification, wherein national AI systems increasingly embody regional technological priorities and cultural contexts. Russia’s pursuit of technological sovereignty has caused the rapid advancement of domestic large language models (LLMs), notably Yandex GPT-5 and GigaChat 2.0 MAX, developed by Russia’s leading IT companies, Yandex and Sber, respectively. Yandex GPT-5, created by the search engine giant Yandex, is optimized for Russian language processing and integrates with the Alice voice assistant. GigaChat 2.0 MAX, developed by the fintech leader Sber, excels in Russian language contexts. These advancements occur amidst international sanctions and an increased emphasis on import substitution. They foster a unique AI innovative ecosystem that balances limited resources with strategic investments in technology and linguistics.
Recent analyses indicate that a substantial share of Russian AI research funding is channeled through state-aligned entities, emphasizing applications that ensure information control and linguistic autonomy. This state-driven approach contrasts with Western commercial paradigms yet yields notable outcomes. For instance, GigaChat 2.0 MAX reports strong accuracy on Russian-language MMLU; Yandex’s Alice integration with GPT-5 highlights a tailored approach to Cyrillic processing and Slavic linguistic structures.
While Western models demonstrate scale and versatility, Russian LLMs prioritize efficiency—approaching top-tier coding accuracy with fewer computational resources. However, cross-cultural evaluation remains limited relative to U.S. research. This study addresses a gap by systematically comparing Russian and global LLMs’ strengths and limitations for organizational performance, offering a framework that accounts for cultural and linguistic variation.
II. METHODOLOGY
This study adopts a mixed-methods framework to assess five LLMs relevant to business tasks—ChatGPT 4o, Grok 3, DeepSeek V3, GigaChat 2.0 MAX, and Yandex GPT-5. The approach combines: (i) custom-designed tasks, (ii) Chatbot/LM Arena comparative data, and (iii) standardized benchmarks (MMLU in Russian/English, GSM8K, MATH, HumanEval, IFEVAL in Russian/English).
Custom tasks. We designed five categories: logical reasoning (binary scoring), mathematics (partial credit), programming (JavaScript “Snake” game; functionality 0–2), social media (Instagram post; creativity 1–5), and image generation (futuristic city; panel-averaged accuracy).
LM Arena. Elo-based rankings compare listed global models; for models not present (GigaChat 2.0 MAX, Yandex GPT-5), we estimate relative performance via simulated pairwise comparisons or analogous methods.
Benchmarks. Standard datasets provide objective metrics for language comprehension, math reasoning, coding, and instruction-following.
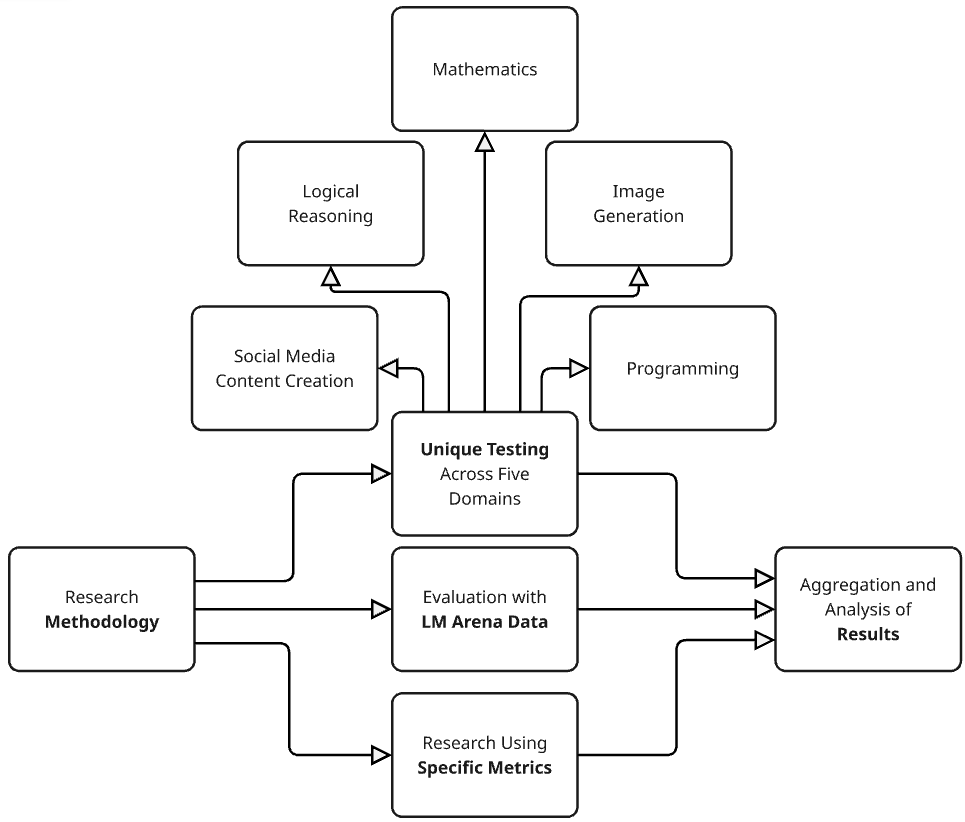
Figure 1. Flowchart with research methodology.
III. RESULTS
All models showed proficiency in logic and mathematics, reaching maximum scores in custom tasks. In programming, ChatGPT 4o, Grok 3, and DeepSeek V3 produced fully functional solutions. Yandex GPT-5 scored lower due to outdated web design output, and GigaChat 2.0 MAX failed to produce an executable game. For social media, DeepSeek V3 excelled in creativity. In image generation, ChatGPT 4o performed best; Yandex GPT-5 and GigaChat 2.0 MAX were moderate performers; DeepSeek V3 lacks image generation capability.
Table I. Brief version AI test
| Task Type |
ChatGPT-4o |
Grok-3 |
DeepSeek V3 |
GigaChat 2.0 MAX |
Yandex GPT-5 |
| Logical reasoning tasks | 5 | 5 | 5 | 5 | 5 |
| Mathematical tasks | 3 | 3 | 3 | 3 | 3 |
| Programming | 4 | 4 | 4 | 2 | 2 |
| SMM (creativity) | 4 | 4 | 4 | 5 | 3 |
| Image generation | 5 | 4 | 3 | 4 | 4 |
| Total score | 21 | 20 | 17 | 16 | 17 |
Arena & benchmarks. LM Arena (without Russian LLMs) places ChatGPT-4o, Grok-3, and DeepSeek V3 near the top overall and in Russian tasks. Benchmarks indicate GigaChat 2.0 MAX is competitive in Russian-language MMLU and IFEVAL, while DeepSeek V3 leads on HumanEval and English IFEVAL. These results highlight Russian LLMs’ strength in native language contexts and the balanced capabilities of global models across categories.
IV. CONCLUSION
Yandex GPT-5 and GigaChat 2.0 MAX exhibit performance levels close to global models across business-relevant tasks. Their strengths in logical reasoning and mathematics are on par with peers; modest gaps remain in programming and creative outputs, reflecting resource constraints rather than inherent limits. In Russian-language benchmarks, Russian models can partially outperform Western counterparts, underscoring the value of linguistic specialization. With continued state-aligned investment and targeted innovation, Russian LLMs may further close gaps—especially within Russian tasks—while maintaining competitive standing globally.
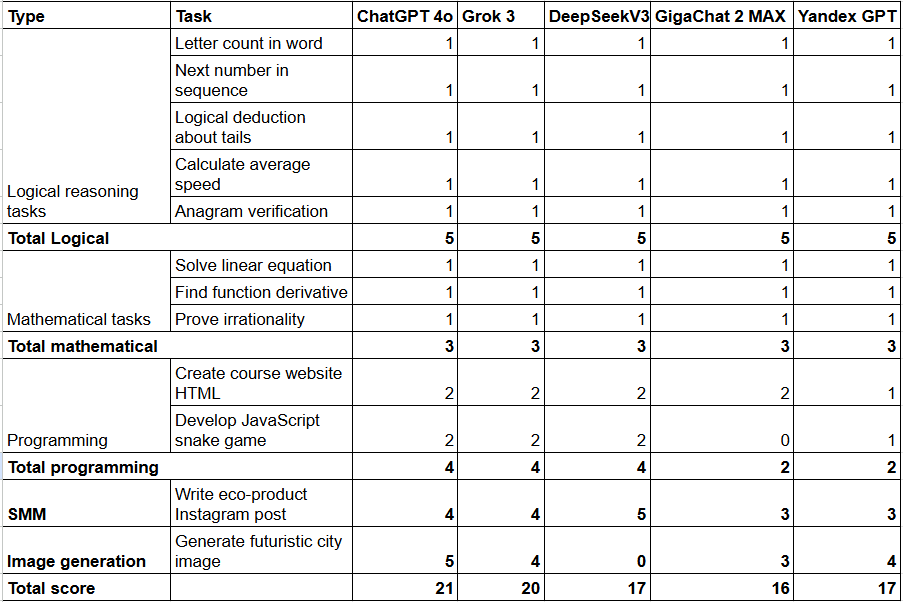
Figure 3. Detailed results and scores for each model across the evaluated tasks.
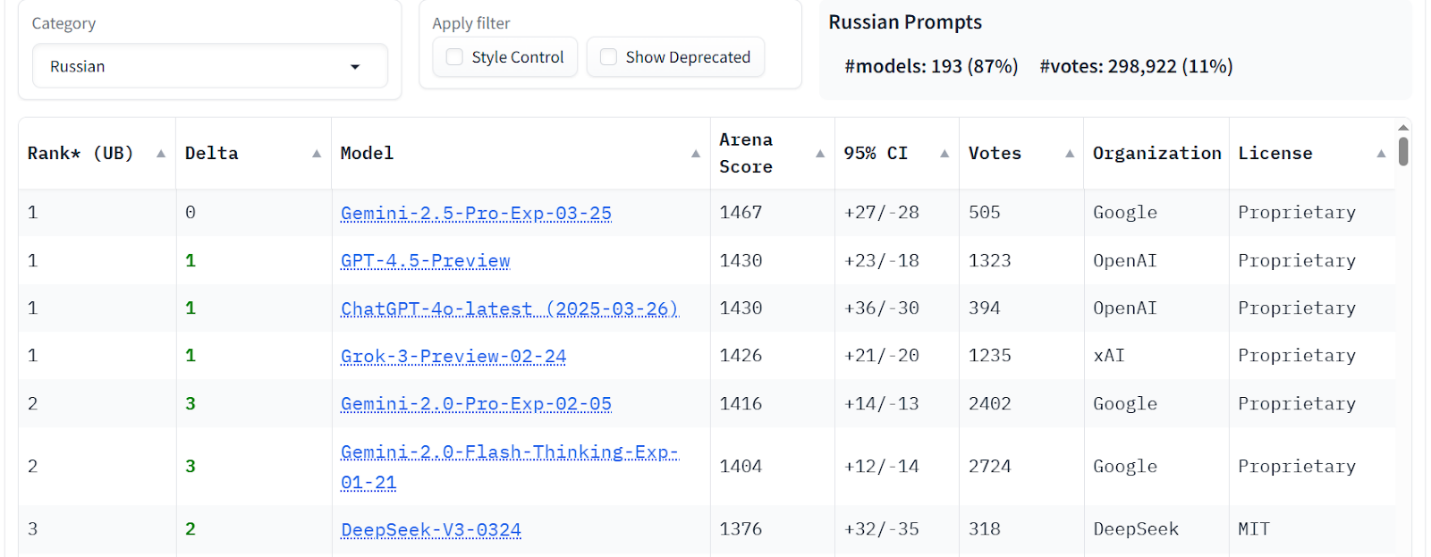
Figure 4. LM Arena data – Russian tasks score.
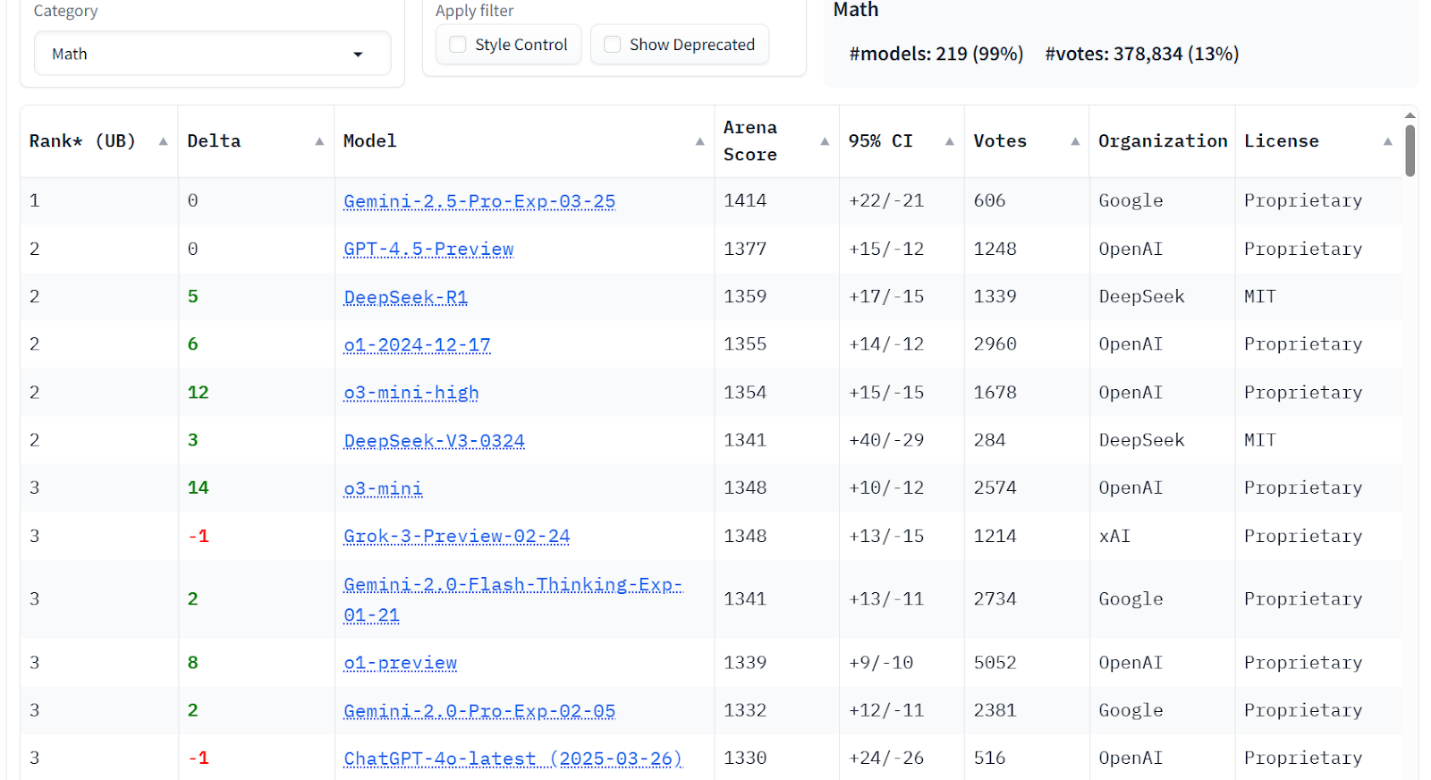
Figure 5. LM Arena data – Mathematical tasks score.
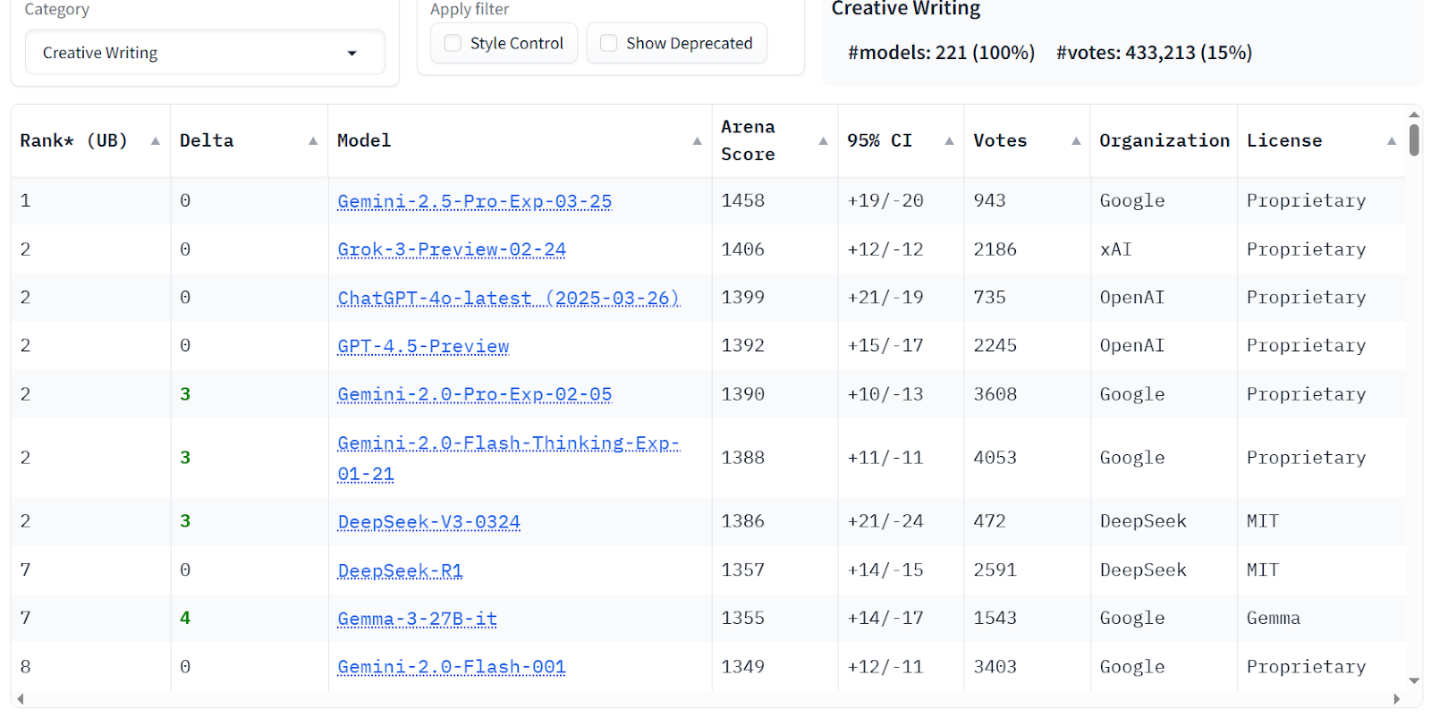
Figure 6. LM Arena data – Creative tasks score.
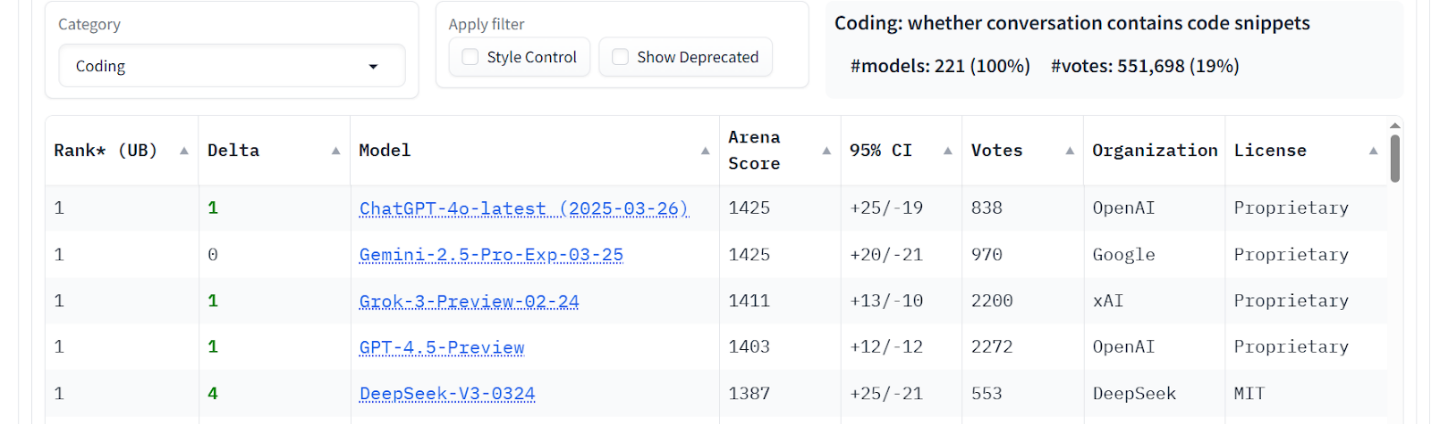
Figure 7. LM Arena data – Coding tasks score.
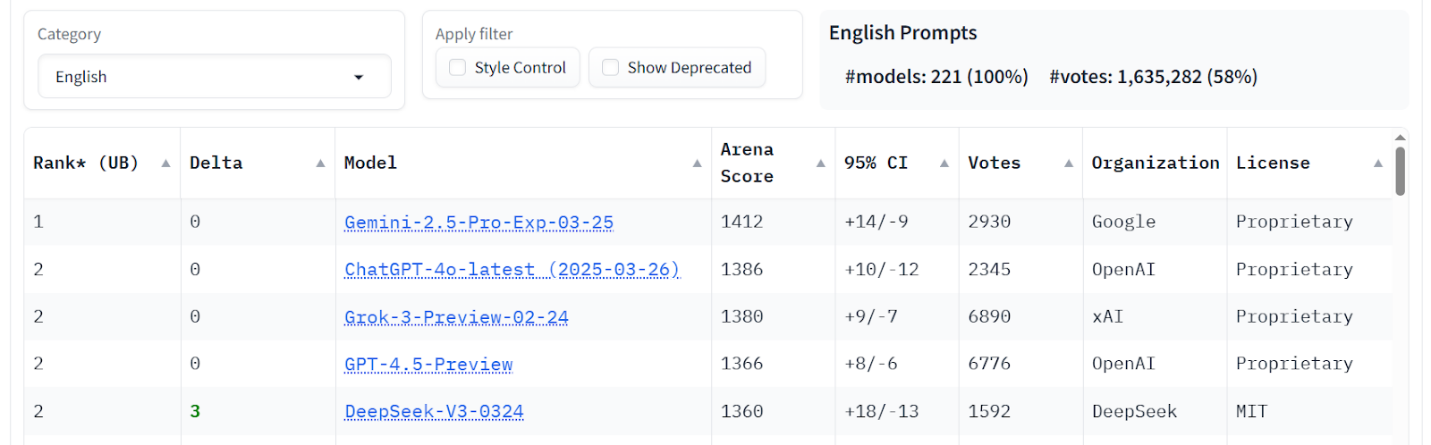
Figure 8. LM Arena data – English tasks score.
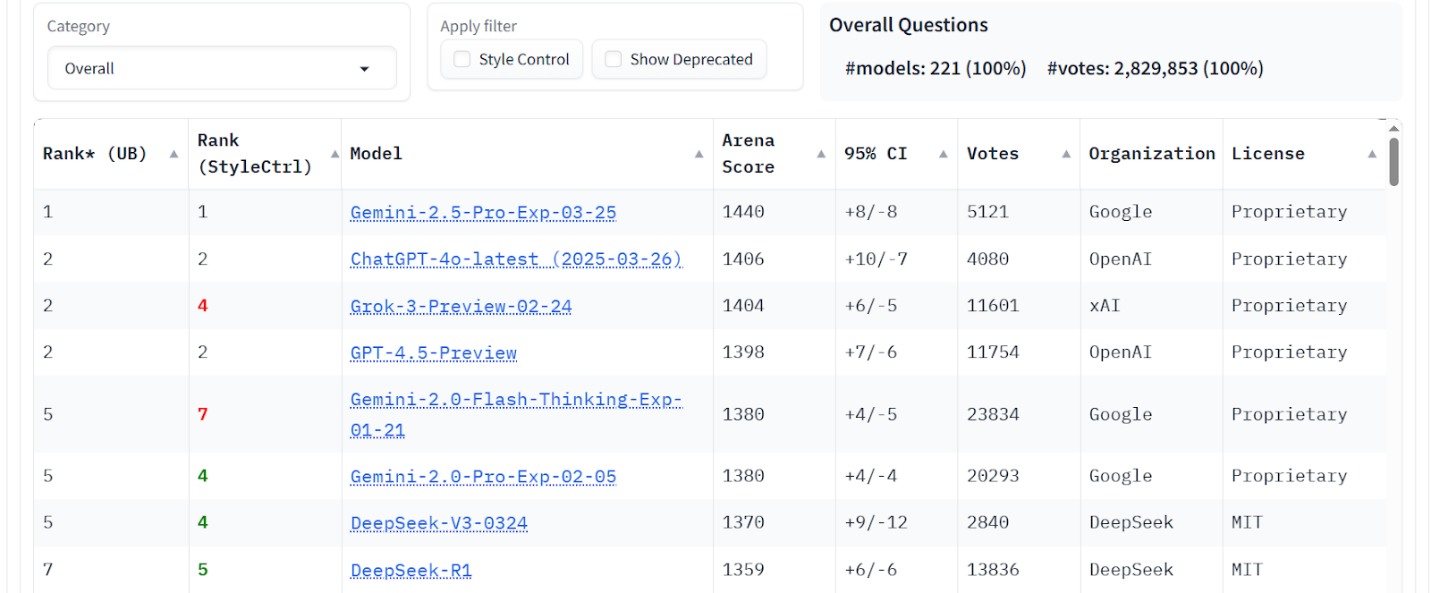
Figure 9. LM Arena data – Overall score.
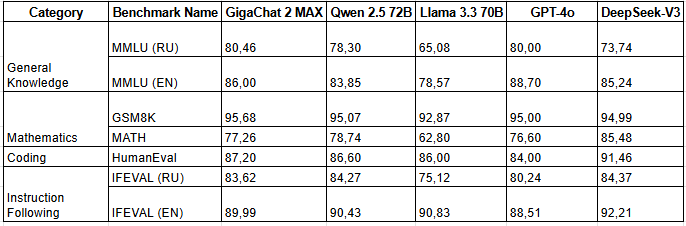
Figure 10. Tests of models based on metrics by task category.
REFERENCES
[1] Yandex. (n.d.). Alice voice assistant. Retrieved April 22, 2025, from https://alice.yandex.ru/
[2] Sber. (n.d.). GigaChat. Retrieved April 22, 2025, from https://giga.chat/
[3] Center for Naval Analyses. (2024). Artificial intelligence and autonomy in Russia. Retrieved April 4, 2025, from https://www.cna.org/centers-and-divisions/cna/sppp/russia-studies/artificial-intelligence-and-autonomy-in-russia
[4] Geneva Internet Platform. (2024, February 11). Russia struggles to catch up in global AI race. Retrieved April 4, 2025, from https://dig.watch/updates/russia-struggles-to-catch-up-in-global-ai-race
[5] Popkova, E. G., & Stefanovic, M. (2024). [TRENDS OF THE AI ECONOMY IN RUSSIA]. Journal of Artificial Intelligence, 1(1), 1–10. https://jai.aspur.rs/archive/v1/n1/1.pdf
[6] Evrim Ağacı. (2025, February 25). YandexGPT-5 Pro revolutionizes AI with Alice integration. Retrieved April 4, 2025, from https://evrimagaci.org/tpg/yandexgpt-5-pro-revolutionizes-ai-with-alice-integration-227608
[7] The Hans India. (2025, March 13). Sber presents new neural network GigaChat 2.0. Retrieved April 4, 2025, from https://www.thehansindia.com/business/sber-presents-new-neural-network-gigachat-20-953634
[8] Konaev, M., & Gilli, A. (2020). Russian AI research 2010 to 2018. Center for Security and Emerging Technology. https://cset.georgetown.edu/wp-content/uploads/CSET-Russian-AI-Research-2010-to-2018-2.pdf
[9] Future Skills Academy. (2025, February 25). GPT-5 vs GPT-4. Retrieved April 4, 2025, from https://futureskillsacademy.com/blog/gpt-5-vs-gpt-4/
[10] Fello AI. (2024, August). Claude AI: Everything you need to know. Retrieved April 4, 2025, from https://felloai.com/2024/08/claude-ai-everything-you-need-to-know/
[11] Chen, D., Esperança, J. P., & Wang, S. (2022). The impact of artificial intelligence on firm performance: An application of the resource-based view to e-commerce firms. Frontiers in Psychology, 13, 884830. https://doi.org/10.3389/fpsyg.2022.884830
[12] DataCube Research. (2024, June). Russia generative AI market: Analysis 2019–2032 (Report AI4212). Niche Industry Monitor.
[13] Business Insider. (2024). US, China compete for AI dominance while Russia's model lags behind. Retrieved April 4, 2025, from https://www.businessinsider.com/us-china-compete-ai-dominance-while-russia-model-lags-behind-2025-2
[14] OpenAI. (n.d.). ChatGPT. Retrieved April 22, 2025, from https://chatgpt.com/
[15] xAI. (n.d.). Grok. Retrieved April 22, 2025, from https://grok.com/
[16] DeepSeek. (n.d.). DeepSeek chat. Retrieved April 22, 2025, from https://chat.deepseek.com
[17] Chatbot Arena. (2024). LM Arena Leaderboard. Retrieved April 4, 2025, from https://arena.lmsys.org/
[18] Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring massive multitask language understanding. arXiv. https://arxiv.org/abs/2009.03300
[19] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training verifiers to solve math word problems. arXiv. https://arxiv.org/abs/2110.14168
[20] Jagtap, A. D., Shin, Y., Kawaguchi, K., & Karniadakis, G. E. (2022). Deep Kronecker neural networks: A general framework for neural networks with adaptive activation functions. Neurocomputing, 468, 165–180.
[21] Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. de O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., … Zaremba, W. (2021). Evaluating large language models trained on code. arXiv. https://arxiv.org/abs/2107.03374
[22] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P. F., Leike, J., & Lowe, R. (2022). Training language models to follow instructions with human feedback. NeurIPS, 35, 27730–27744.
[23] T-J.ru. (2025, March 13). Sber GigaChat 2. Retrieved April 4, 2025, from https://t-j.ru/news/sber-gigachat-2/